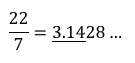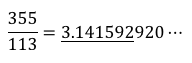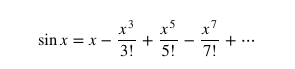こんにちは。 久しぶりにプログラマー向けの記事です。 bc と言うコマンドが、知れば知るほど素晴らしすぎるので、その凄さを知っている範囲で紹介します。「そんなの知っている」と言う方はスルーでお願いします。
bc コマンドとは
Unix の標準コマンド(SUS Shell and Utilities)の1つで、任意精度の計算を行うコマンドです。例えば Mac OS X は Unix ですので、標準でインストールされています。Windows で使用したい場合は別途インストールする必要が有ります。
使い方(基本編)
起動
Mac OS X で使用する場合の例を紹介します。 まず Dock からターミナルを起動して bc と入力します。
|
|
<span style="color: #000000;">$</span> <span style="color: #0000ff;"><strong>bc</strong></span> <span style="color: #999999;">bc 1.06 Copyright 1991-1994, 1997, 1998, 2000 Free Software Foundation, Inc. This is free software with ABSOLUTELY NO WARRANTY. For details type `warranty'. </span> |
するとクレジット情報が表示され、入力待ちになります。プロンプトはありません。
式の入力
例えば “1+2” を計算したい場合は、そのように入力してリターンキーを押します。
|
|
<span style="color: #0000ff;"><strong>1+2</strong></span> |
|
|
<strong><span style="color: #999999;">3 </span></strong> |
答えは “3” ですね。 デフォルト状態で、四則演算(+, -, *, /)、剰余(%)、累乗(^)、平方根(sqrt)などが使えます。 ちょっとした計算、例えば平均値の計算などが、通常の電卓よりは計算しやすいと思います。
|
|
<span style="color: #0000ff;"><strong>(69+80+22+95)/4</strong></span> |
|
|
<span style="color: #999999;"><strong>66</strong></span> |
小数点以下の桁数を指定
デフォルト状態では、小数点以下の値は切り捨てられますが、scale と言う特殊変数に値を設定することで、小数の計算結果も得られます。例えば、小数点以下3位までの結果を表示させるには以下のようにします。
|
|
<strong><span class="s1" style="color: #0000ff;">scale=3</span></strong> |
|
|
<strong><span class="s1" style="color: #0000ff;">10/3</span></strong> |
|
|
<strong><span class="s1"><span style="color: #999999;">3.333</span> </span></strong> |
終了
終了するときは quit と入力します。
|
|
<span style="color: #0000ff;"><strong>quit</strong></span> |
応用編
2進/10進/16進の相互変換(ibase, obase)
このあたりから非常に有用になってきます。 bc は、ibase, obase という変数に値を指定することで、入力と出力に使用する進数を自由に指定できます。
16進数 98A0B0223F を 10進数に変換する
|
|
<span style="color: #0000ff;"><strong><span class="s1">obase=10</span></strong></span> |
|
|
<span style="color: #0000ff;"><strong><span class="s1">ibase=16</span></strong></span> |
|
|
<span style="color: #0000ff;"><strong><span class="s1">98A0B0223F</span></strong></span> |
|
|
<strong><span class="s1"><span style="color: #999999;">655530926655</span> </span></strong> |
10進数 1234 を2進数に変換する
|
|
<span style="color: #0000ff;"><strong><span class="s1">ibase=10</span></strong></span> |
|
|
<span style="color: #0000ff;"><strong><span class="s1">obase=2</span></strong></span> |
|
|
<span style="color: #0000ff;"><strong><span class="s1">1234</span></strong></span> |
|
|
<span class="s1"><span style="color: #999999;"><strong>10011010010</strong></span> </span> |
10進数 987.6543 を 16進数に変換する(「16進の小数」なども普通に扱えます!)
|
|
<span style="color: #0000ff;"><strong><span class="s1">ibase=10</span></strong></span> |
|
|
<span style="color: #0000ff;"><strong><span class="s1">obase=16</span></strong></span> |
|
|
<span style="color: #0000ff;"><strong><span class="s1">987.6543</span></strong></span> |
|
|
<span style="color: #999999;"><strong><span class="s1">3DB.A780</span></strong></span> |
ひとつ注意点があります。 ibaseを10以外の値にしてしまうと、それ以降入力する値はすべてその進数で入力しなければなりません。例えば以下の例は思うように動作しないでしょう。そのため、obaseを ibaseより先に設定するのが無難です。
16進->10進変換(失敗例)
|
|
<span style="color: #0000ff;"><strong><span class="s1">ibase=16 <== ここで入力は16進数になる</span></strong></span> |
|
|
<span style="color: #0000ff;"><strong><span class="s1">obase=<span style="color: #ff0000;">10 <== これは "10h" とみなされ、obase(出力)も16進数になる</span></span></strong></span> |
|
|
<span style="color: #0000ff;"><strong><span class="s1">A</span></strong></span> |
|
|
<span style="color: #ff0000;"><strong><span class="s1">A <= ??</span></strong></span> |
π の計算(初等関数の使用)
起動時に “-l” (小文字のエル)オプションを付加すると、サイン (s), コサイン (c), アークタンジェント (a), 自然対数 log (l), exp (e), ベッセル関数 (j) が使用できます。このとき scale は自動的に 20 に設定されます。
|
|
<strong><span class="s1">$ <span style="color: #0000ff;">bc -l </span></span></strong><span style="color: #808080;"><strong><span class="s1">bc 1.06 </span></strong><strong><span class="s1">Copyright 1991-1994, 1997, 1998, 2000 Free Software Foundation, Inc. </span></strong><strong><span class="s1">This is free software with ABSOLUTELY NO WARRANTY. </span></strong><strong><span class="s1">For details type `warranty'. </span></strong><strong><span class="s1"><span style="color: #0000ff;">a(1)*4</span> </span></strong></span><strong><span class="s1"><span style="color: #808080;">3.14159265358979323844</span> </span></strong> |
ここで、アークタンジェント1が π/4 だと言うことを利用し、a(1)*4 で π を求めています。これは数値計算の定石です・・・よね。 scale を 1000 とかにしても、いけます!
|
|
<span style="color: #0000ff;"><strong><span class="s1">scale=1000</span></strong></span> |
|
|
<span style="color: #0000ff;"><strong><span class="s1">a(1)*4</span></strong></span> |
|
|
<span style="color: #808080;"><strong><span class="s1">3.141592653589793238462643383279502884197169399375105820974944592307\</span></strong></span> |
|
|
<span style="color: #808080;"><strong><span class="s1">81640628620899862803482534211706798214808651328230664709384460955058\</span></strong></span> |
|
|
<span style="color: #808080;"><strong><span class="s1">22317253594081284811174502841027019385211055596446229489549303819644\</span></strong></span> |
|
|
<span style="color: #808080;"><strong><span class="s1">28810975665933446128475648233786783165271201909145648566923460348610\</span></strong></span> |
|
|
<span style="color: #808080;"><strong><span class="s1">45432664821339360726024914127372458700660631558817488152092096282925\</span></strong></span> |
|
|
<span style="color: #808080;"><strong><span class="s1">40917153643678925903600113305305488204665213841469519415116094330572\</span></strong></span> |
|
|
<span style="color: #808080;"><strong><span class="s1">70365759591953092186117381932611793105118548074462379962749567351885\</span></strong></span> |
|
|
<span style="color: #808080;"><strong><span class="s1">75272489122793818301194912983367336244065664308602139494639522473719\</span></strong></span> |
|
|
<span style="color: #808080;"><strong><span class="s1">07021798609437027705392171762931767523846748184676694051320005681271\</span></strong></span> |
|
|
<span style="color: #808080;"><strong><span class="s1">45263560827785771342757789609173637178721468440901224953430146549585\</span></strong></span> |
|
|
<span style="color: #808080;"><strong><span class="s1">37105079227968925892354201995611212902196086403441815981362977477130\</span></strong></span> |
|
|
<span style="color: #808080;"><strong><span class="s1">99605187072113499999983729780499510597317328160963185950244594553469\</span></strong></span> |
|
|
<span style="color: #808080;"><strong><span class="s1">08302642522308253344685035261931188171010003137838752886587533208381\</span></strong></span> |
|
|
<span style="color: #808080;"><strong><span class="s1">42061717766914730359825349042875546873115956286388235378759375195778\</span></strong></span> |
|
|
<span style="color: #808080;"><strong><span class="s1">18577805321712268066130019278766111959092164201988</span></strong></span> |
そう、π は男のロマン・・・。 誤差はほとんどありません!最後の桁は(4でかけてることもあり)合わないことが多いですが、その1つ前の桁は正しいと思っていいようです。(厳密な話をすると長くなるので割愛します・・・)
π を16進数で表示
ここで obase=16 にすると、16進数で π が表示できたりします!
|
|
<span style="color: #0000ff;"><strong><span class="s1">scale=20</span></strong></span> |
|
|
<span style="color: #0000ff;"><strong><span class="s1">obase=16</span></strong></span> |
|
|
<span style="color: #0000ff;"><strong><span class="s1">a(1)*4</span></strong></span> |
|
|
<span class="s1"><span style="color: #808080;"><strong>3.243F6A8885A308D2A</strong></span> </span> |
16進数の π が標準コマンドで、こんな手軽に表示できるとは! しかもPCの計算能力が許すまでいくらでも!
\(^o^)/
オイラー数 e についても e(1) とすれば表示されるので、同様のことが可能です。すごいです。 プログラマーとしては押さえておきたいコマンドですね!